Analyzing Twitter Data with Apache Hadoop 20 Mar 2014
目前社交媒体在市场开发中凸显了巨大的作用,Twitter是一个公司让人们对它的产品产生极大兴趣的一个工具。Twitter让人和公司之间能够直接交流。公司可以借由Twitter获知用户对其产品的兴趣。对于给定限定资源,公司不能与每一个用户去交流,所以市场开发的效率取决于是否能够选择最有价值的客户来交流。
谁是有价值的?{#who-is-valuable}
假设有一个用户,我们叫他Joe,他follow了一些人,而且也拥有一些followers。当Joe发了一个更新,该更新会被其所有followers看到。Joe同时也在转发其他用户的更新。一条转发是一个更新的重新发送,就像你转发一封邮件。如果Joe看到Sue的一条tweet,并且转发了它,Joe所有的followers都会看到Sue的tweet,即使他们没有follow Sue。通过转发,消息可以传递给发送tweet的人的followers以外。知道了这个,我们试图鼓励用户生成大量的转发。由于Twitter记录了所有tweet的转发数,我们可以通过分析Twitter的数据来找到我们正在寻找的客户。
现在我们知道我们想要问的问题:哪些Twitter用户得到了最多的转发?谁对于我们来说是最有价值的?
我们如何回答这些问题?
SQL查询可以用来回答这些问题:我们可以按照tweets的转发数倒序排列,看到哪些用户的tweets的转发数最多。然而,在传统RDBMS中查询Twitter的数据是很不方便的,由于Twitter Streaming API是用JSON格式输出tweets,并且JSON可能任意复杂。在Hadoop生态环境中,Hive项目提供了一个可以用来查询HDFS中的数据的查询接口,它的查询语言和SQL很相似,但是允许我们方便得对复杂类型建模,这样我们可以方便地查询我们拥有的数据类型。这样的话,我们就需要考虑,我们如何将Twitter的数据放入Hive?首先,我们需要将Twitter的数据放入HDFS,然后我们告诉Hive数据在哪儿存放以及如何去读取。
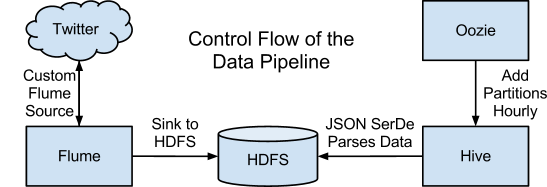
上图显示了一些CDH组件拼合在一起建立数据管道来解决我们的问题的一个结构图。下面我们介绍这些组件如何交互以及它们所扮演的角色。
使用Apache Flume收集数据
Twitter Streaming API为我们提供了一个来源于服务的tweets的固定流。一个选择是使用一个类似于curl的简单工具访问API,然后周期性的载入文件。然而,这要求我们写代码来控制数据存放在HDFS的位置,并且如果我们有一个安全集群,我们必须还得集成安全机制。使用CDH组件来自动将文件通过API存入HDFS更为简单,并不需要我们的手动介入。
Apache Flume是一个数据接收系统,它通过配置叫做sources和sinks的来确定一个数据流的终结点。在Flume中,每一个独立的数据(tweets)叫做一个事件;sources产生events,并将events通过一个连接着source和sink的channel发送出去。然后sink将事件输出给一个预定义的位置。Flume支持一些标准数据源,类似于syslog或netcat。对于我们来说,我们需要设计一个自定义的source来访问Twitter Streaming API,然后通过一个channel发送tweets给一个输出到HDFS文件的sink。此外,我们需要使用自定义的source来通过一系列搜索关键词来过滤tweets来辨别相关的tweets,而不是一整个twitter的纯样本。
/**
* A Flume Source, which pulls data from Twitter's streaming API. Currently,
* this only supports pulling from the sample API, and only gets new status
* updates.
*/
public class TwitterSource extends AbstractSource
implements EventDrivenSource, Configurable {
private static final Logger logger =
LoggerFactory.getLogger(TwitterSource.class);
/** Information necessary for accessing the Twitter API */
private String consumerKey;
private String consumerSecret;
private String accessToken;
private String accessTokenSecret;
private String[] keywords;
/** The actual Twitter stream. It's set up to collect raw JSON data */
private final TwitterStream twitterStream = new TwitterStreamFactory(
new ConfigurationBuilder()
.setJSONStoreEnabled(true)
.build()).getInstance();
/**
* The initialization method for the Source. The context contains all the
* Flume configuration info, and can be used to retrieve any configuration
* values necessary to set up the Source.
*/
@Override
public void configure(Context context) {
consumerKey = context.getString(TwitterSourceConstants.CONSUMER_KEY_KEY);
consumerSecret = context.getString(TwitterSourceConstants.CONSUMER_SECRET_KEY);
accessToken = context.getString(TwitterSourceConstants.ACCESS_TOKEN_KEY);
accessTokenSecret = context.getString(TwitterSourceConstants.ACCESS_TOKEN_SECRET_KEY);
String keywordString = context.getString(TwitterSourceConstants.KEYWORDS_KEY, "");
keywords = keywordString.split(",");
for (int i = 0; i < keywords.length; i++) {
keywords[i] = keywords[i].trim();
}
}
/**
* Start processing events. This uses the Twitter Streaming API to sample
* Twitter, and process tweets.
*/
@Override
public void start() {
// The channel is the piece of Flume that sits between the Source and Sink,
// and is used to process events.
final ChannelProcessor channel = getChannelProcessor();
final Map<String, String> headers = new HashMap<String, String>();
// The StatusListener is a twitter4j API, which can be added to a Twitter
// stream, and will execute methods every time a message comes in through
// the stream.
StatusListener listener = new StatusListener() {
// The onStatus method is executed every time a new tweet comes in.
public void onStatus(Status status) {
// The EventBuilder is used to build an event using the headers and
// the raw JSON of a tweet
logger.debug(status.getUser().getScreenName() + ": " + status.getText());
headers.put("timestamp", String.valueOf(status.getCreatedAt().getTime()));
Event event = EventBuilder.withBody(
DataObjectFactory.getRawJSON(status).getBytes(), headers);
channel.processEvent(event);
}
// This listener will ignore everything except for new tweets
public void onDeletionNotice(StatusDeletionNotice statusDeletionNotice) {}
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {}
public void onScrubGeo(long userId, long upToStatusId) {}
public void onException(Exception ex) {}
};
logger.debug("Setting up Twitter sample stream using consumer key {} and" +
" access token {}", new String[] { consumerKey, accessToken });
// Set up the stream's listener (defined above), and set any necessary
// security information.
twitterStream.addListener(listener);
twitterStream.setOAuthConsumer(consumerKey, consumerSecret);
AccessToken token = new AccessToken(accessToken, accessTokenSecret);
twitterStream.setOAuthAccessToken(token);
// Set up a filter to pull out industry-relevant tweets
if (keywords.length == 0) {
logger.debug("Starting up Twitter sampling...");
twitterStream.sample();
} else {
logger.debug("Starting up Twitter filtering...");
FilterQuery query = new FilterQuery()
.track(keywords)
.setIncludeEntities(true);
twitterStream.filter(query);
}
super.start();
}
/**
* Stops the Source's event processing and shuts down the Twitter stream.
*/
@Override
public void stop() {
logger.debug("Shutting down Twitter sample stream...");
twitterStream.shutdown();
super.stop();
}
}详细代码可参见这里
使用Oozie进行切分管理
当我们将Twitter的数据存储到HDFS上,我们可以利用它在Hive创建一个外部表来查询。使用外部表可以让我们在查询时不需要将数据从它在HDFS最终位置上移动到其他位置。为了确保系统的可伸缩性,在我们的数据量越来越大时,我们将需要对表进行切分。分区表可以使查询时读取的文件量减少,在处理大数据时,会更有效率。然而,当我们不断使用Twitter API获取tweets,Flume将不断创建新文件。在新数据到来时,我们需要自动为我们的表添加分区。
Apache Oozie是一个工作流协调系统,它可以用来解决这一问题。Oozie是用来设计工作流的一个灵活的系统,它可以基于一系列规则来定时运行。我们配置工作流运行一个ALTER TABLE命令将过去一小时的数据创建一个分区到Hive,并且我们指定该工作流每小时执行一次。这将确保我们一直能够关注于最新的数据。
Oozie的配置文件可以参见这里。
使用Hive查询复杂数据
在查询数据之前,我们需要确保Hive表能够解析JSON数据。默认情况下,Hive只能解析delimited row format,但是我们拿到的Twitter数据是JSON格式的,默认Hive是无法解析的。这其实是Hive的一个最大优势。Hive允许我们自由地定义,重定义数据如何存储在磁盘上。只有在我们读取数据时,模式schema才是固定的,我们可以使用Hive SerDe接口来确定如何解析我们加载的数据。
SerDe表示Serializer和Deserializer接口,它们告诉Hive如果将数据转换成Hive可以处理的形式。其中,Deserializer接口用来从磁盘读取数据,并将数据转换成Hive知道如何处理的对象。一旦它们被存放到指定位置,我们就可以开始查询。SerDe获取如下的JSON格式的tweet
{
"retweeted_status": {
"contributors": null,
"text": "#Crowdsourcing – drivers already generate traffic data for your smartphone to suggest alternative routes when a road is clogged. #bigdata",
"geo": null,
"retweeted": false,
"in_reply_to_screen_name": null,
"truncated": false,
"entities": {
"urls": [],
"hashtags": [
{
"text": "Crowdsourcing",
"indices": [
0,
14
]
},
{
"text": "bigdata",
"indices": [
129,
137
]
}
],
"user_mentions": []
},
"in_reply_to_status_id_str": null,
"id": 245255511388336128,
"in_reply_to_user_id_str": null,
"source": "SocialOomph",
"favorited": false,
"in_reply_to_status_id": null,
"in_reply_to_user_id": null,
"retweet_count": 0,
"created_at": "Mon Sep 10 20:20:45 +0000 2012",
"id_str": "245255511388336128",
"place": null,
"user": {
"location": "Oregon, ",
"default_profile": false,
"statuses_count": 5289,
"profile_background_tile": false,
"lang": "en",
"profile_link_color": "627E91",
"id": 347471575,
"following": null,
"protected": false,
"favourites_count": 17,
"profile_text_color": "D4B020",
"verified": false,
"description": "Dad, Innovator, Sales Professional. Project Management Professional (PMP). Soccer Coach, Little League Coach #Agile #PMOT - views are my own -",
"contributors_enabled": false,
"name": "Scott Ostby",
"profile_sidebar_border_color": "404040",
"profile_background_color": "0F0F0F",
"created_at": "Tue Aug 02 21:10:39 +0000 2011",
"default_profile_image": false,
"followers_count": 19005,
"profile_image_url_https": "https://si0.twimg.com/profile_images/1928022765/scott_normal.jpg",
"geo_enabled": true,
"profile_background_image_url": "http://a0.twimg.com/profile_background_images/327807929/xce5b8c5dfff3dc3bbfbdef5ca2a62b4.jpg",
"profile_background_image_url_https": "https://si0.twimg.com/profile_background_images/327807929/xce5b8c5dfff3dc3bbfbdef5ca2a62b4.jpg",
"follow_request_sent": null,
"url": "http://facebook.com/ostby",
"utc_offset": -28800,
"time_zone": "Pacific Time (US & Canada)",
"notifications": null,
"friends_count": 13172,
"profile_use_background_image": true,
"profile_sidebar_fill_color": "1C1C1C",
"screen_name": "ScottOstby",
"id_str": "347471575",
"profile_image_url": "http://a0.twimg.com/profile_images/1928022765/scott_normal.jpg",
"show_all_inline_media": true,
"is_translator": false,
"listed_count": 45
},
"coordinates": null
},
"contributors": null,
"text": "RT @ScottOstby: #Crowdsourcing – drivers already generate traffic data for your smartphone to suggest alternative routes when a road is ...",
"geo": null,
"retweeted": false,
"in_reply_to_screen_name": null,
"truncated": false,
"entities": {
"urls": [],
"hashtags": [
{
"text": "Crowdsourcing",
"indices": [
16,
30
]
}
],
"user_mentions": [
{
"id": 347471575,
"name": "Scott Ostby",
"indices": [
3,
14
],
"screen_name": "ScottOstby",
"id_str": "347471575"
}
]
},
"in_reply_to_status_id_str": null,
"id": 245270269525123072,
"in_reply_to_user_id_str": null,
"source": "web",
"favorited": false,
"in_reply_to_status_id": null,
"in_reply_to_user_id": null,
"retweet_count": 0,
"created_at": "Mon Sep 10 21:19:23 +0000 2012",
"id_str": "245270269525123072",
"place": null,
"user": {
"location": "",
"default_profile": true,
"statuses_count": 1294,
"profile_background_tile": false,
"lang": "en",
"profile_link_color": "0084B4",
"id": 21804678,
"following": null,
"protected": false,
"favourites_count": 11,
"profile_text_color": "333333",
"verified": false,
"description": "",
"contributors_enabled": false,
"name": "Parvez Jugon",
"profile_sidebar_border_color": "C0DEED",
"profile_background_color": "C0DEED",
"created_at": "Tue Feb 24 22:10:43 +0000 2009",
"default_profile_image": false,
"followers_count": 70,
"profile_image_url_https": "https://si0.twimg.com/profile_images/2280737846/ni91dkogtgwp1or5rwp4_normal.gif",
"geo_enabled": false,
"profile_background_image_url": "http://a0.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https": "https://si0.twimg.com/images/themes/theme1/bg.png",
"follow_request_sent": null,
"url": null,
"utc_offset": null,
"time_zone": null,
"notifications": null,
"friends_count": 299,
"profile_use_background_image": true,
"profile_sidebar_fill_color": "DDEEF6",
"screen_name": "ParvezJugon",
"id_str": "21804678",
"profile_image_url": "http://a0.twimg.com/profile_images/2280737846/ni91dkogtgwp1or5rwp4_normal.gif",
"show_all_inline_media": false,
"is_translator": false,
"listed_count": 7
},
"coordinates": null
}并将JSON实体转换成可查询的列
SELECT created_at, entities, text, user
FROM tweets
WHERE user.screen_name='ParvezJugon'
AND retweeted_status.user.screen_name='ScottOstby';最终形成结果
| created_at | Mon Sep 10 21:19:23 +0000 2012 |
| entities | {"urls":[],"user_mentions":[{"screen_name":"ScottOstby","name":"Scott Ostby"}],"hashtags":[{"text":"Crowdsourcing"}]} |
| text | RT @ScottOstby: #Crowdsourcing – drivers already generate traffic data for your smartphone to suggest alternative routes when a road is ... |
| user | {"screen_name":"ParvezJugon","name":"Parvez Jugon","friends_count":299,"followers_count":70,"statuses_count":1294,"verified":false,"utc_offset":null,"time_zone":null} |
JSON SerDe代码如下
/**
* This SerDe can be used for processing JSON data in Hive. It supports
* arbitrary JSON data, and can handle all Hive types except for UNION.
* However, the JSON data is expected to be a series of discrete records,
* rather than a JSON array of objects.
*
* The Hive table is expected to contain columns with names corresponding to
* fields in the JSON data, but it is not necessary for every JSON field to
* have a corresponding Hive column. Those JSON fields will be ignored during
* queries.
*
* Example:
*
* { "a": 1, "b": [ "str1", "str2" ], "c": { "field1": "val1" } }
*
* Could correspond to a table:
*
* CREATE TABLE foo (a INT, b ARRAY<STRING>, c STRUCT<field1:STRING>);
*
* JSON objects can also interpreted as a Hive MAP type, so long as the keys
* and values in the JSON object are all of the appropriate types. For example,
* in the JSON above, another valid table declaraction would be:
*
* CREATE TABLE foo (a INT, b ARRAY<STRING>, c MAP<STRING,STRING>);
*
* Only STRING keys are supported for Hive MAPs.
*/
public class JSONSerDe implements SerDe {
private StructTypeInfo rowTypeInfo;
private ObjectInspector rowOI;
private List<String> colNames;
private List<Object> row = new ArrayList<Object>();
/**
* An initialization function used to gather information about the table.
* Typically, a SerDe implementation will be interested in the list of
* column names and their types. That information will be used to help perform
* actual serialization and deserialization of data.
*/
@Override
public void initialize(Configuration conf, Properties tbl)
throws SerDeException {
// Get a list of the table's column names.
String colNamesStr = tbl.getProperty(serdeConstants.LIST_COLUMNS);
colNames = Arrays.asList(colNamesStr.split(","));
// Get a list of TypeInfos for the columns. This list lines up with
// the list of column names.
String colTypesStr = tbl.getProperty(serdeConstants.LIST_COLUMN_TYPES);
List<TypeInfo> colTypes =
TypeInfoUtils.getTypeInfosFromTypeString(colTypesStr);
rowTypeInfo =
(StructTypeInfo) TypeInfoFactory.getStructTypeInfo(colNames, colTypes);
rowOI =
TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(rowTypeInfo);
}
/**
* This method does the work of deserializing a record into Java objects that
* Hive can work with via the ObjectInspector interface. For this SerDe, the
* blob that is passed in is a JSON string, and the Jackson JSON parser is
* being used to translate the string into Java objects.
*
* The JSON deserialization works by taking the column names in the Hive
* table, and looking up those fields in the parsed JSON object. If the value
* of the field is not a primitive, the object is parsed further.
*/
@Override
public Object deserialize(Writable blob) throws SerDeException {
Map<?,?> root = null;
row.clear();
try {
ObjectMapper mapper = new ObjectMapper();
// This is really a Map<String, Object>. For more information about how
// Jackson parses JSON in this example, see
// http://wiki.fasterxml.com/JacksonDataBinding
root = mapper.readValue(blob.toString(), Map.class);
} catch (Exception e) {
throw new SerDeException(e);
}
// Lowercase the keys as expected by hive
Map<String, Object> lowerRoot = new HashMap();
for(Map.Entry entry: root.entrySet()) {
lowerRoot.put(((String)entry.getKey()).toLowerCase(), entry.getValue());
}
root = lowerRoot;
Object value= null;
for (String fieldName : rowTypeInfo.getAllStructFieldNames()) {
try {
TypeInfo fieldTypeInfo = rowTypeInfo.getStructFieldTypeInfo(fieldName);
value = parseField(root.get(fieldName), fieldTypeInfo);
} catch (Exception e) {
value = null;
}
row.add(value);
}
return row;
}
/**
* Parses a JSON object according to the Hive column's type.
*
* @param field - The JSON object to parse
* @param fieldTypeInfo - Metadata about the Hive column
* @return - The parsed value of the field
*/
private Object parseField(Object field, TypeInfo fieldTypeInfo) {
switch (fieldTypeInfo.getCategory()) {
case PRIMITIVE:
// Jackson will return the right thing in this case, so just return
// the object
if (field instanceof String) {
field = field.toString().replaceAll("\n", "\\\\n");
}
return field;
case LIST:
return parseList(field, (ListTypeInfo) fieldTypeInfo);
case MAP:
return parseMap(field, (MapTypeInfo) fieldTypeInfo);
case STRUCT:
return parseStruct(field, (StructTypeInfo) fieldTypeInfo);
case UNION:
// Unsupported by JSON
default:
return null;
}
}
/**
* Parses a JSON object and its fields. The Hive metadata is used to
* determine how to parse the object fields.
*
* @param field - The JSON object to parse
* @param fieldTypeInfo - Metadata about the Hive column
* @return - A map representing the object and its fields
*/
private Object parseStruct(Object field, StructTypeInfo fieldTypeInfo) {
Map<Object,Object> map = (Map<Object,Object>)field;
ArrayList<TypeInfo> structTypes = fieldTypeInfo.getAllStructFieldTypeInfos();
ArrayList<String> structNames = fieldTypeInfo.getAllStructFieldNames();
List<Object> structRow = new ArrayList<Object>(structTypes.size());
for (int i = 0; i < structNames.size(); i++) {
structRow.add(parseField(map.get(structNames.get(i)), structTypes.get(i)));
}
return structRow;
}
/**
* Parse a JSON list and its elements. This uses the Hive metadata for the
* list elements to determine how to parse the elements.
*
* @param field - The JSON list to parse
* @param fieldTypeInfo - Metadata about the Hive column
* @return - A list of the parsed elements
*/
private Object parseList(Object field, ListTypeInfo fieldTypeInfo) {
ArrayList<Object> list = (ArrayList<Object>) field;
TypeInfo elemTypeInfo = fieldTypeInfo.getListElementTypeInfo();
for (int i = 0; i < list.size(); i++) {
list.set(i, parseField(list.get(i), elemTypeInfo));
}
return list.toArray();
}
/**
* Parse a JSON object as a map. This uses the Hive metadata for the map
* values to determine how to parse the values. The map is assumed to have
* a string for a key.
*
* @param field - The JSON list to parse
* @param fieldTypeInfo - Metadata about the Hive column
* @return
*/
private Object parseMap(Object field, MapTypeInfo fieldTypeInfo) {
Map<Object,Object> map = (Map<Object,Object>) field;
TypeInfo valueTypeInfo = fieldTypeInfo.getMapValueTypeInfo();
for (Map.Entry<Object,Object> entry : map.entrySet()) {
map.put(entry.getKey(), parseField(entry.getValue(), valueTypeInfo));
}
return map;
}
/**
* Return an ObjectInspector for the row of data
*/
@Override
public ObjectInspector getObjectInspector() throws SerDeException {
return rowOI;
}
/**
* Unimplemented
*/
@Override
public SerDeStats getSerDeStats() {
return null;
}
/**
* JSON is just a textual representation, so our serialized class
* is just Text.
*/
@Override
public Class<? extends Writable> getSerializedClass() {
return Text.class;
}
/**
* This method takes an object representing a row of data from Hive, and uses
* the ObjectInspector to get the data for each column and serialize it. This
* implementation deparses the row into an object that Jackson can easily
* serialize into a JSON blob.
*/
@Override
public Writable serialize(Object obj, ObjectInspector oi)
throws SerDeException {
Object deparsedObj = deparseRow(obj, oi);
ObjectMapper mapper = new ObjectMapper();
try {
// Let Jackson do the work of serializing the object
return new Text(mapper.writeValueAsString(deparsedObj));
} catch (Exception e) {
throw new SerDeException(e);
}
}
/**
* Deparse a Hive object into a Jackson-serializable object. This uses
* the ObjectInspector to extract the column data.
*
* @param obj - Hive object to deparse
* @param oi - ObjectInspector for the object
* @return - A deparsed object
*/
private Object deparseObject(Object obj, ObjectInspector oi) {
switch (oi.getCategory()) {
case LIST:
return deparseList(obj, (ListObjectInspector)oi);
case MAP:
return deparseMap(obj, (MapObjectInspector)oi);
case PRIMITIVE:
return deparsePrimitive(obj, (PrimitiveObjectInspector)oi);
case STRUCT:
return deparseStruct(obj, (StructObjectInspector)oi, false);
case UNION:
// Unsupported by JSON
default:
return null;
}
}
/**
* Deparses a row of data. We have to treat this one differently from
* other structs, because the field names for the root object do not match
* the column names for the Hive table.
*
* @param obj - Object representing the top-level row
* @param structOI - ObjectInspector for the row
* @return - A deparsed row of data
*/
private Object deparseRow(Object obj, ObjectInspector structOI) {
return deparseStruct(obj, (StructObjectInspector)structOI, true);
}
/**
* Deparses struct data into a serializable JSON object.
*
* @param obj - Hive struct data
* @param structOI - ObjectInspector for the struct
* @param isRow - Whether or not this struct represents a top-level row
* @return - A deparsed struct
*/
private Object deparseStruct(Object obj,
StructObjectInspector structOI,
boolean isRow) {
Map<Object,Object> struct = new HashMap<Object,Object>();
List<? extends StructField> fields = structOI.getAllStructFieldRefs();
for (int i = 0; i < fields.size(); i++) {
StructField field = fields.get(i);
// The top-level row object is treated slightly differently from other
// structs, because the field names for the row do not correctly reflect
// the Hive column names. For lower-level structs, we can get the field
// name from the associated StructField object.
String fieldName = isRow ? colNames.get(i) : field.getFieldName();
ObjectInspector fieldOI = field.getFieldObjectInspector();
Object fieldObj = structOI.getStructFieldData(obj, field);
struct.put(fieldName, deparseObject(fieldObj, fieldOI));
}
return struct;
}
/**
* Deparses a primitive type.
*
* @param obj - Hive object to deparse
* @param oi - ObjectInspector for the object
* @return - A deparsed object
*/
private Object deparsePrimitive(Object obj, PrimitiveObjectInspector primOI) {
return primOI.getPrimitiveJavaObject(obj);
}
private Object deparseMap(Object obj, MapObjectInspector mapOI) {
Map<Object,Object> map = new HashMap<Object,Object>();
ObjectInspector mapValOI = mapOI.getMapValueObjectInspector();
Map<?,?> fields = mapOI.getMap(obj);
for (Map.Entry<?,?> field : fields.entrySet()) {
Object fieldName = field.getKey();
Object fieldObj = field.getValue();
map.put(fieldName, deparseObject(fieldObj, mapValOI));
}
return map;
}
/**
* Deparses a list and its elements.
*
* @param obj - Hive object to deparse
* @param oi - ObjectInspector for the object
* @return - A deparsed object
*/
private Object deparseList(Object obj, ListObjectInspector listOI) {
List<Object> list = new ArrayList<Object>();
List<?> field = listOI.getList(obj);
ObjectInspector elemOI = listOI.getListElementObjectInspector();
for (Object elem : field) {
list.add(deparseObject(elem, elemOI));
}
return list;
}
}现在我们将以上所有组件拼合,用Twitter Stream API获取数据,通过Flume将tweets发送给HDFS,并且使用Oozie定期将文件载入Hive,我们使用Hive SerDe可以查询原始JSON数据。
原文地址
Analyzing Twitter Data with Apache Hadoop
下面一章我们将详细介绍如何利用flume收集数据,并将它们存入HDFS,以及flume各个组件的作用。