Elasticsearch Related 29 Nov 2015
以下所有章节都基于Elasticsearch 2.0
Elasticsearch Transport Wires
中文分词引入
Indexes
创建一个索引
curl -XPUT 'localhost:9200/customer?pretty'
// 结果返回
{
"acknowledged" : true
}上面的命令会创建一个名为customer的索引, URL后面添加pretty, 结果返回的json会经过格式化
查看所有索引
curl 'localhost:9200/_cat/indices?v'
// 结果返回
health index pri rep docs.count docs.deleted store.size pri.store.size
yellow customer 5 1 0 0 495b 495b上面命令告诉我们现在总共有1个索引名字叫做customer, 其中包含的Document总数, 被删掉的Document数以及占用空间等信息.
向索引中添加/更新一个Document
- 显式指定ID
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'
// 结果返回
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"created" : true
}上面命令会向customer索引中添加一个类型为external的Document, 这个Document的ID为1, 而且从结果返回中也可以看到索引, 类型, ID, 版本等信息
如果需要更新这个ID为1的Document, 只需使用同样的命令, ES会将请求覆盖掉这个Document
- 不指定ID
curl -XPOST 'localhost:9200/customer/external?pretty' -d '
{
"name": "John Doe"
}'上面的命令没有指定ID, ES会自动为这个Document生成一个ID, 这个ID会在结果返回中返回
注意该命令使用的是POST动词, 而不是PUT
删除一个Document
curl -XDELETE 'localhost:9200/customer/external/2?pretty'该命令会在customer索引的external类型删除ID为2的Document
根据ID获取一个Document
curl -XGET 'localhost:9200/customer/external/1?pretty'
// 结果返回
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"found" : true, "_source" : { "name": "John Doe" }
}通过上面结果返回的found字段表示该查询是否命中, _source字段中包含了Document的内容
删除一个索引
curl -XDELETE 'localhost:9200/customer?pretty'
// 结果返回
{
"acknowledged" : true
}该命令会删除整个customer索引
ES索引切片(Shards)工作原理
在ES中, 每一个索引对应于一个或多个切片, 索引在ES中是一个逻辑空间, 而切片是真正的数据存放的物理空间, 它们散落在集群的各个节点中. 与ES交互的个体并不知道切片的存在, 他们直接与索引进行交互,
当我们索引一个文档时, 文档存储在一个单独的主切片中. 那么当我们索引一个文档时, 我们如何该文档处于哪个主切片呢?
它可以通过以下公式来决定
shard = hash(routing) % number_of_primary_shards
其中routing值默认是Document的_id, 当然也可以自己设置. 该值会被传到hash函数中获得一个hash值, 将该hash值与number_of_primary_shards取模, 得到的shard值介于0 ~ number_of_primary_shards-1之间, 该document会存储在该值对应的shard中.
所以, 一个索引的主切片数(number_of_primary_shards)必须在索引创建时指定, 并且不能在中途做变更, 因为一旦更新后, 之前的documents有可能无法被正常找到
标题没想好, 后面看内容定(基于5.3.X)
ES启动过程
- 创建PID文件
- 检测Lucene版本
- 如果是*nux, 检测是否是root账户执行
- 根据配置, 启用
system call filter,mlockall, 设置启动ES进程用户的最大进程数和最大虚拟内存数等操作 - 做一些启动前环境检测
- 检测jvm启动时初始堆内存与最大堆内存是否一致 - 由于初始内存和最大堆内存不一致的话, 在系统运行过程中根据内存用量会重新分配jvm占用内存大小, 从而导致jvm暂停
- 检测File descriptors最大数
- 检测内存锁 - JVM在做GC时, 有可能会将堆内存中的数据换到硬盘上, 而在进行后续与数据相关的操作时必须再将硬盘中的数据换回内存, 导致大量的磁盘操作
- 最大线程数检测
- 最大虚拟内存检测 - ES和Lucene使用
mmap来将索引文件映射到内存加速索引的访问 - 和上一点类似, 为了让ES更有效率的使用
mmap, 需要检测ES进程启动用户所能控制的最大内存映射大小 - 检测jvm版本不是client版
- 检测GC不能使用
-XX:+UseSerialGC, SerialGC适合用于单核, 或小内存的机器 - 检测是否启用
system call filter, 出于考虑, 启用system call filter来避免系统通过ES执行一些非法系统调用 - 检测是否设置了JVM启动参数
OnError和OnOutOfMemoryError, 这两个标识允许JVM遇到Error后执行任意的命令, 这与上一项有冲突, 所以必须保证这两项参数不能被启用 - jdk8早期版本中G1GC会导致索引损坏, 检测当G1GC启用后, 没有使用这些版本(prior to Update 40)
- 在每个节点根据该节点设置的数据目录
path.data(可能有多个)尝试获取节点锁, 如果其中一个数据目录获取失败, 则重新建立另外一个锁目录, 直至超过配置数node.max_local_storage_nodesNodeEnvironment - 载入配置中指定的
${path.home}/plugins和${path.home}/modules目录中的所有插件, 并实例化它们的插件实例, 例如public class Netty4Plugin extends Plugin implements NetworkPlugin { ... }PluginsService - 创建一个含有操作类型的线程池, 每种操作类型都会映射到一个独立的线程池, 这些线程池根据实际用途拥有不同的线程数, 队列长度, 任务舍弃策略等 ThreadPool
- 利用插件构建不同服务, 例如
NetworkService, ClusterService, TransportService等, 并启动这些服务
NetworkPlugin启动时, 会根据配置(默认netty4)启动指定的TCP和HTTP服务 Netty4Transport.doStart
ES请求线程模型
以HTTP请求(推荐使用)为例, 当Node1接收到HTTP请求, 该请求直接在监听HTTP协议的EventLoopGroup的一个线程中预执行,
- 如果后续操作可以在本地运行, 那么剩下的操作则在当前这个线程执行
- 如果后续操作需要在其他节点执行, 则请求会被分发到另外的节点, 该节点接收到TCP请求后, 根据请求所属的线程池类型, 分配对应的线程池进行执行

Index操作/Bulk操作
- 索引操作被委派给
TransportIndexAction来执行, 最终也会将该请求转发给TransportBulkAction执行 - Bulk操作被委派给
TransportBulkAction来执行
所以我们主要沿着TransportBulkAction的流程往下梳理
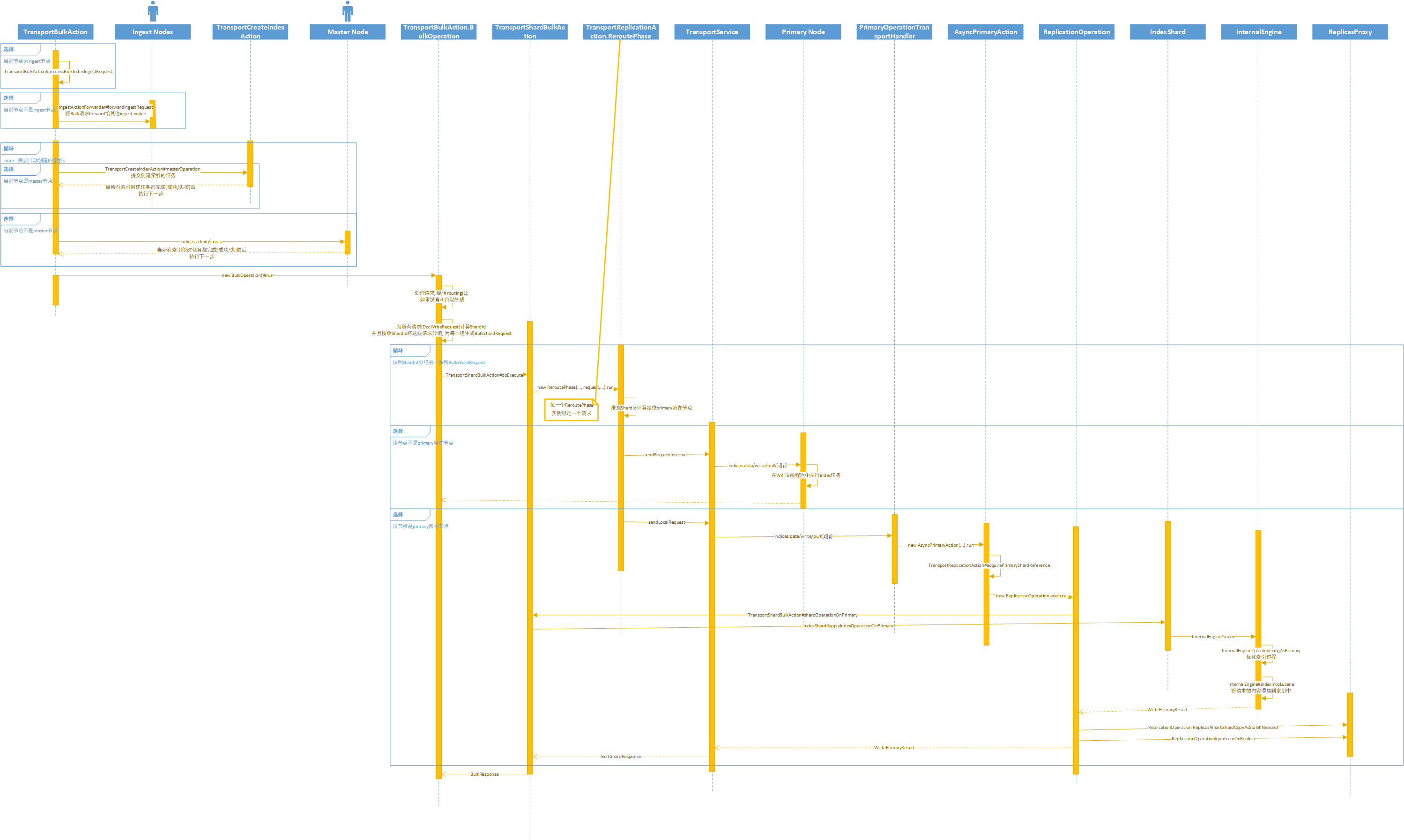
TransportBulkAction#onExecute: 检查request是否包含pipeline, 如果包含pipeline, 则将该请求发送到ingest节点进行处理(如果本节点就是ingest节点, 那么直接在本地处理ingest请求), 如果本请求中涉及到的索引不存在, 则将创建索引的请求发送到Master节点, 待所有索引创建完毕后, 执行bulk命令;TransportBulkAction.BulkOperation#doRun: 根据索引以及参数中的routing和id计算ShardId,ShardId由Index和整型类型的shardId构成, 比如将一个索引分为n个shard,shardId是从0开始到n-1的碎片标识. 后续根据ShardId将请求中的每一个请求项进行分组, 并为每一个ShardId其包含的一系列请求项生成一个BulkShardRequest, 之后将这些BulkShardRequests分发给TransportShardBulkAction执行, 每一个ShardId执行一次;TransportShardBulkAction#doExecute:TransportShardBulkAction继承自TransportReplicationAction, 该方法执行的实际是TransportReplicationAction.doExecute, 该方法的内容是new ReroutePhase((ReplicationTask) task, request, listener).run();, 每一个ShardId都会创建一个ReroutePhase来对应一个BulkShardRequest;TransportReplicationAction.ReroutePhase#doRun: 根据ShardId确定该请求对应的主分片所在, 如果主分片处于当前节点, 则执行本地请求; 否则执行远程请求, 将请求发送给主分片所在的节点;- 请求发送:
TransportReplicationAction.ReroutePhase#performAction->TransportService#sendRequest->TransportService#sendRequestInternal** 远程请求(TcpTransport.NodeChannels#sendRequest->TcpTransport#internalSendMessage->NettyTcpChannel#sendMessage): 会将请求转发给主切片所在的节点, 通信使用TCP协议. 在ES启动时会根据transport插件(默认netty4)来决定使用哪种实现, 并且在启动时还会建立与各个节点的连接, 并存放在Map中, 以DiscoveryNode为Key, 发送请求时, 根据被请求节点的DiscoveryNode对象获取连接, 并在该连接写入请求, 该请求可以序列化; ** 本地请求(TransportService#sendLocalRequest): 执行本地请求方法路径为TransportService#sendLocalRequest; - 请求处理:
** 远程请求: 请求发送到主分片所在的节点之后, 该节点监听的tcp端口接收到字节请求,
Netty4MessageChannelHandler#channelRead->TcpTransport#messageReceived->TcpTransport#handleRequest, 通过接收到的字节请求中读取出action, 根据action来确定其RequestHandlerRegistry, 并且使用该RequestHandlerRegistry实例将接收到的字节请求构建为一个ConcreteShardRequest实例, 该实例中包含一个BulkShardRequest实例, 根据这个reg实例的executor值(ThreadPool.Names.WRITE)确定好线程池, 以本操作为例是FIXED线程池, 线程池大小为机器的处理器数量, queue大小为200. 在该线程池执行RequestHandlerRegistry#processMessageReceived(request, channel); ** 本地请求:TransportService#sendLocalRequest方法中传递的TransportResponseHandler中重写了executor为TheadPool.SAME, 即在当前线程执行RequestHandlerRegistry#processMessageReceived(request, channel); RequestHandlerRegistry#processMessageReceived(request, channel): 根据actionName(BulkAction.NAME + "[s]" + "[p]")确定实际执行的方法为PrimaryOperationTransportHandler#messageReceived, 而该方法的内容是new AsyncPrimaryAction(...).run();TransportReplicationAction.AsyncPrimaryAction#doRun: 该方法执行的是acquirePrimaryShardReference(..., ActionListener<PrimaryShardReference> onReferenceAcquired, ...), 其中onReferenceAcquired为TransportReplicationAction.AsyncPrimaryAction实例自身, 其执行流程为先获取主碎片操作许可, 成功获取后则执行TransportReplicationAction.AsyncPrimaryAction#onResponse, 在执行bulk操作前, 需要先判断主碎片是否还在当前节点, 如果不在的话, 则直接发送执行请求给主碎片所在节点, 而不需重新获取操作许可; 如果主碎片还处于当前节点, 那么直接执行AsyncPrimaryAction#createReplicatedOperation.execute(), 该方法实际内容是new ReplicationOperation.execute();ReplicationOperation#execute: 接下来执行TransportReplicationAction.PrimaryShardReference#perform->TransportShardBulkAction#shardOperationOnPrimary;TransportShardBulkAction#shardOperationOnPrimary: 该方法执行的实际内容是TransportShardBulkAction#executeBulkItemRequest, 由于我们追踪的是Index操作, 所以接下来执行TransportShardBulkAction#executeIndexRequest的方法;TransportShardBulkAction#executeIndexRequest: 该方法将请求构建为一个SourceToParse实例, 如果需要动态更新Mapping, 则请求更新Mapping, 而后再请求IndexShard#applyIndexOperationOnPrimary->IndexShard#applyIndexOperation->IndexShard#index->InternalEngine#index;InternalEngine#index: 实际的索引方法, 在实际执行索引请求之前, ES会优化索引过程, 具体优化过程参见ES索引逻辑优化章节, 该方法执行完毕后, 继续执行ReplicationOperation#execute方法后续部分, 从index方法返回的结果中获取ReplicaRequest, 并执行复制请求ReplicationOperation#performOnReplicas;ReplicationOperation#performOnReplicas: 该方法需要将该切片对应的副本置为过期数据, 然后为每一个副本执行ReplicationOperation#performOnReplica;ReplicationOperation#performOnReplica: 该方法执行的内容是TransportReplicationAction.ReplicasProxy#performOn;TransportReplicationAction.ReplicasProxy#performOn: 获取副本所在的节点, 发送复制请求(BulkAction.NAME + "[s]" + "[r]")到该节点, 对应节点接收到复制请求, 在副本所在节点根据actionName(BulkAction.NAME + "[s]" + "[r]")确定在副本节点执行TransportReplicationAction.ReplicaOperationTransportHandler#messageReceived方法, 该方法执行的内容是new AsyncReplicaAction(...).run();TransportReplicationAction.AsyncReplicaAction#doRun: 该方法执行的是IndexShard#acquireReplicaOperationPermit(..., ActionListener<Releasable> onPermitAcquired, ...), 其中onPermitAcquired为TransportReplicationAction.AsyncReplicaAction实例自身, 其执行流程为先获取碎片副本的操作许可, 成功获取后则执行TransportReplicationAction.AsyncReplicaAction#onResponse->TransportShardBulkAction#shardOperationOnReplica->TransportShardBulkAction#performOnReplica, 处于这个碎片副本的所有索引操作(或者其他操作)item都将在这个方法中执行;TransportShardBulkAction#performOnReplica: 迭代BulkShardRequest请求中的每一个DocWriteRequest请求, 以上述在主碎片中执行对应请求为正常返回为例, 将该DocWriteRequest和主碎片对应的返回等信息传入给TransportShardBulkAction#performOpOnReplica方法;TransportShardBulkAction#performOpOnReplica: 该方法执行的内容是IndexShard#applyIndexOperationOnReplica->IndexShard#applyIndexOperation->IndexShard#index->InternalEngine#index, 该方法根据副本的索引策略进行优化, 然后再进行索引.
Bulk操作的简要流程如下图所示
搜索
拿非跨集群的搜索举例, 跨集群搜索与集群内搜索处理方式唯一的不同是跨集群搜索需要建立与其他集群的连接, 而这个连接可以看做集群内的一个到任意DiscoveryNode的连接 TransportSearchAction#doExecute -> RemoteClusterService#collectSearchShards
TransportSearchAction#doExecute: 获取搜索请求SearchRequest涉及到的索引, 并检查是否有属于其他集群的索引, 如果有的话则执行RemoteClusterService#collectSearchShards方法收集涉及到的集群的搜索结果, 合并后向请求方返回, 本例中只以集群内搜索为例, 所以该方法下一步直接执行TransportSearchAction#executeSearch;TransportSearchAction#executeSearch: 根据搜索请求中的索引和routing计算Shards, 并根据Shards个数, 查询类型等优化设置search_type, 而后调用TransportSearchAction#searchAsyncAction;TransportSearchAction#searchAsyncAction: 如果search_type为DFS_QUERY_THEN_FETCH, 则执行SearchDfsQueryThenFetchAsyncAction#execute; 如果search_type为QUERY_THEN_FETCH, 则执行SearchQueryThenFetchAsyncAction#execute; 这两个SearchAction都继承自InitialSearchPhaseInitialSearchPhase#execute: 为每一个ShardId按顺序选择一个Shard进行搜索命令; **SearchDfsQueryThenFetchAsyncAction#execute: 向选择的Shard发送搜索请求indices:data/read/search[phase/dfs]; **SearchQueryThenFetchAsyncAction#execute: 向选择的Shard发送搜索请求indices:data/read/search[phase/query];- 请求接收:
**
indices:data/read/search[phase/dfs]: 根据SearchTransportService#registerRequestHandler的内容, 执行SearchService#executeDfsPhase
根据请求中indies参数解析出具体的索引列表, 解析indies中带有通配符或日期函数的表达式, 将它们映射成为一系列具体的索引, 检查是否有索引别名与参数中的表达式所匹配, 一一将它们解析出来 IndexNameExpressionResolver#concreteIndices 获取indies参数中包含的索引别名关联的Filters, 这些过滤器在执行搜索操作前合并到查询条件的filter上下文中 TransportSearchAction#buildPerIndexAliasFilter 根据请求中indies参数以及routing参数与设置索引别名时指定的routing计算每个索引名对应的routing列表的关系 IndexNameExpressionResolver#resolveSearchRouting 通过上一步的结果计算每一个分片的迭代器, 这个分片迭代器会随机选择该分片中任意一个副本 OperationRouting#searchShards 针对每一个分片, 依次获取该分片(副本)所在节点的连接, 然后通过该连接发送分片查询请求 SearchTransportService#sendExecuteQuery 节点在接收到查询请求后, 在该节点执行查询操作, 内部根据查询请求记录条数以及查询结果等做了一些优化, 这一步完成后, 会得到该分片下符合查询条件记录条数以及查询区间中docId以及分数 QueryPhase#execute 当所有分片查询完成后, 根据分数将所有分片的返回结果进行合并, 重新排序 AbstractSearchAsyncAction$FetchPhase#run -> SearchPhaseController#sortDocs 然后分别统计每个分片下的docId列表, 再向这些分片所在节点发送fetch请求, 该请求包含位于这个分片下所有符合查询条件的docId SearchPhaseController#fillDocIdsToLoad -> AbstractSearchAsyncAction$FetchPhase#executeFetch 该节点获取到fetch请求后, 调用lucene进行获取这些doc的实际内容 FetchPhase#execute 最后, 在上述步骤完成后, 将query步骤产生的目标结果docIds,分数等和fetch步骤中获取的doc的实际内容做合并, 并返回给请求方 AbstractSearchAsyncAction#sendResponseAsync -> SearchPhaseController#merge
在上面步骤中假定search_type指定为默认的query_then_fetch, 除了该默认设置选项, 还有dfs_query_then_fetch项, 它和默认选项的唯一区别就是在执行query阶段之前向各个索引获取额外的一些信息用来进行计分(TF/IDF), 由于默认项query_then_fetch在计分时, 计算TF和IDF时都是在单分片范围内计算的, 使用dfs_query_then_fetch选项在整个索引下所有分片范围内可以获得精确的TF/IDF值
Discovery
要理清Discovery的工作方式, 我们假定有一个集群里包含4个节点, 并且设置discovery.zen.minimum_master_nodes为3(4/2 + 1), discovery.zen.ping.unicast.hosts都为["node1", "node2", "node3", "node4"]
master node是唯一一个能够更新集群状态节点, 当master node将集群状态从A改为B以后, 会将B广播给其他节点, 其他节点在收到广播后, 会告知master node已收到, 但是不会马上更新自己的集群状态; 如果master node在一段时间discovery.zen.commit_timeout内未收到至少discovery.zen.minimum_master_nodes个节点的回馈的话, 此次更新会回退
一旦收到足够的回馈, 此次变更会被提交, 并发送消息给所有节点, 所有节点修改它们内部的集群状态; master node在执行队列中下一次集群状态变更之前会等待所有节点的修改回复
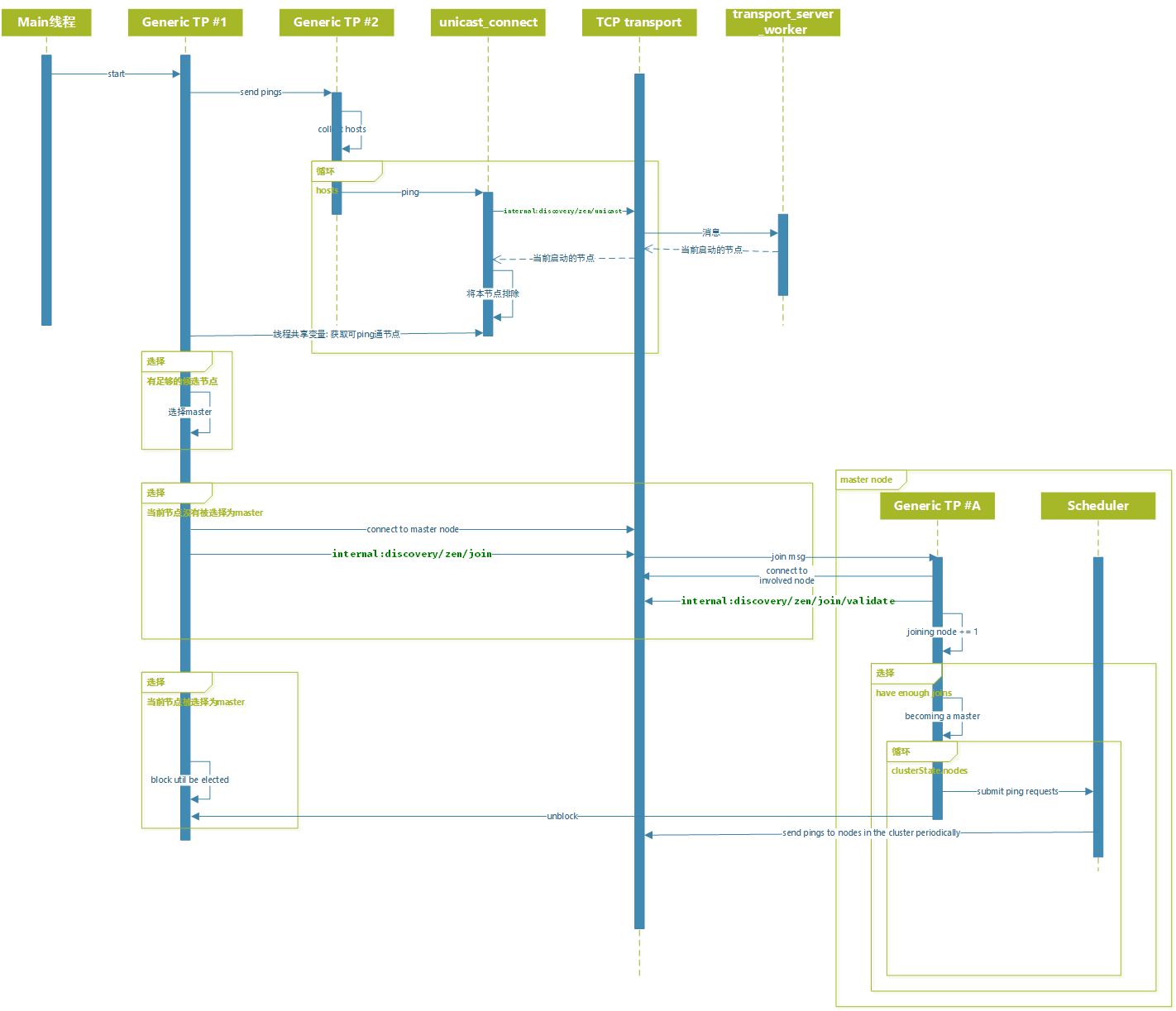
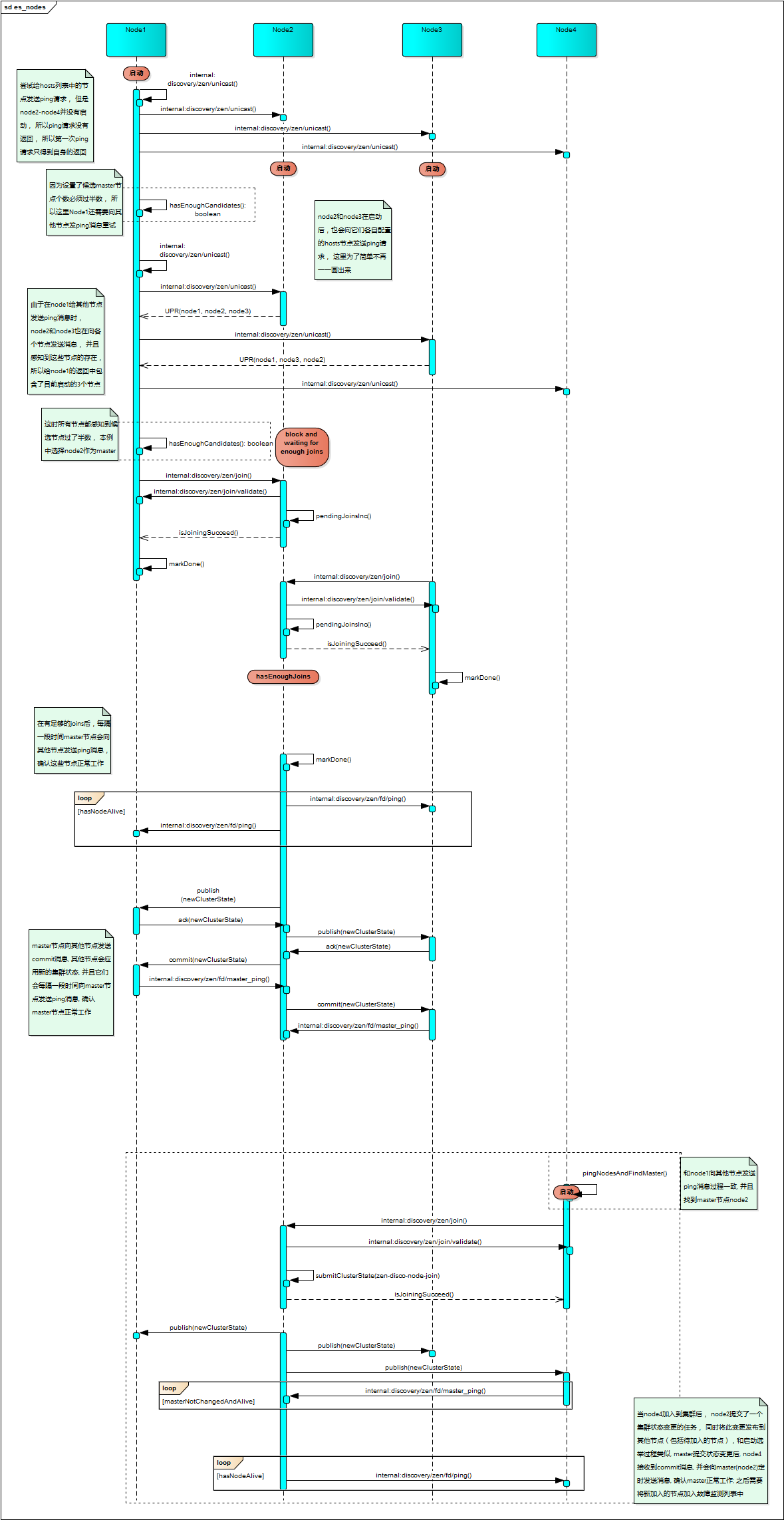
Node#start: ES一系列的服务启动, 并且获取Discovery实例, 并启动, 默认配置下执行的是ZenDiscovery#doStart, 而后调用ZenDiscovery#startInitialJoin方法;ZenDiscovery#ZenDiscovery:ZenDiscovery的构造方法中, 构造了多个实例之后, 会注册internal:discovery/zen/rejoin使用RejoinClusterRequestHandler进行处理; **MasterFaultDetection实例会注册internal:discovery/zen/fd/master_ping请求使用MasterPingRequestHandler进行处理; **NodesFaultDetection实例会注册internal:discovery/zen/fd/ping请求使用PingRequestHandler进行处理; **MembershipAction实例会注册internal:discovery/zen/join使用JoinRequestRequestHandler进行处理; 注册internal:discovery/zen/join/validate使用ValidateJoinRequestRequestHandler进行处理; 注册internal:discovery/zen/leave使用LeaveRequestRequestHandler进行处理;ZenDiscovery#doStart: 构建初始状态的ClusterState, 调用JoinThreadControl#start方法, 而后调用ZenPing#start(对于UnicastZenPing#start为空方法);JoinThreadControl#start: 设置running状态为true;ZenDiscovery#startInitialJoin: 调用ZenDiscovery.JoinThreadControl#startNewThreadIfNotRunning方法;ZenDiscovery.JoinThreadControl#startNewThreadIfNotRunning: 确认当前线程仍然持有锁, 并且running状态为true, 接下来在generic线程池执行ZenDiscovery#innerJoinCluster方法;ZenDiscovery#innerJoinCluster: 持续循环执行ZenDiscovery#findMaster, 直到找到或者失去运行信号为止;ZenDiscovery#findMaster: 开始执行ZenDiscovery#pingAndWait;ZenPing#ping: 根据discovery.zen.ping.unicast.hosts配置的主机列表, 为每一个主机发送请求UnicastZenPing#sendPingRequestToNode, 分别发送3次, 而后再调用UnicastZenPing#finishPingingRound; **threadPool.generic().execute(pingSender);**threadPool.schedule(TimeValue.timeValueMillis(scheduleDuration.millis() / 3), ThreadPool.Names.GENERIC, pingSender);**threadPool.schedule(TimeValue.timeValueMillis(scheduleDuration.millis() / 3 * 2), ThreadPool.Names.GENERIC, pingSender);**threadPool.schedule(scheduleDuration, ThreadPool.Names.GENERIC, finishPingingRound);UnicastZenPing#sendPingRequestToNode: 该任务提交到专门的线程池nodeName() + "/" + "unicast_connect", 如果已经连接到了该节点, 则直接获取到该节点的连接, 如果未连接到该节点, 则打开到节点连接TcpTransport#openConnection, 并向该节点发送internal:transport/handshake, 如果接收到handshake的response, 则使用该连接发送internal:discovery/zen/unicast, 接收到该请求的处理器为UnicastPingRequestHandler;UnicastPingRequestHandler#messageReceived: 接收到请求后将请求中包含的pingResponse追加到返回中TransportResponseHandler#handleResponse: 将返回添加到PingCollection, 并在ZenDiscovery#pingAndWait中返回ZenDiscovery#findMaster: 继续往下执行findMaster方法, 并将ZenPing.PingResponse中的node加入待选master列表中, 然后当有足够的待选master节点(discovery.zen.minimum_master_nodes)后, 执行ElectMasterService#electMaster, 选举一个master节点ZenDiscovery#innerJoinCluster: 当获取到一个master节点后, 有两种情况, 一种情况为当前节点被选举为master, 另一种情况当前节点不是master节点 **ZenDiscovery#joinElectedMaster: 该方法处理其他节点被选举为master的情况, 首先要连接到选举的master节点, 然后发送internal:discovery/zen/join请求, 然后在本线程阻塞直到获取到返回; **NodeJoinController#waitToBeElectedAsMaster: 该方法处理当前节点被选举为master的情况, 阻塞当前线程直到有足够的节点discovery.zen.minimum_master_nodes加入;MembershipAction.JoinRequestRequestHandler#messageReceived: master节点接收到某个节点的internal:discovery/zen/join请求, 首先尝试建立与其的连接transportService.connectToNode(node), 然后向该节点同步发送internal:discovery/zen/join/validate直到接收到返回, 然后调用NodeJoinController#handleJoinRequest;NodeJoinController#handleJoinRequest: 提交zen-disco-node-join集群状态变更任务, 任务内容为NodeJoinController.JoinTaskExecutor#execute, 将请求源的节点加入到当前状态的节点(s)中;- 假定集群中又有新的节点开始启动, 同样需要向它配置的hosts节点依次发送
internal:discovery/zen/unicast请求, 与之前的流程不同, 该节点接收到的返回中包含master的信息, 因此该节点可以直接加入以master节点的集群;
下图描述了Discovery过程的线程模型
从节点之间的角度来描述Discovery过程如下图
集群状态更新
MasterService#submitStateUpdateTasks: 集群状态更新的任务提交给了master节点上的TaskBatcher#submitTasks;TaskBatcher#submitTasks: 该方法接收到一系列的BatchedTask, 这些被一批提交的任务必须使用一个batchingKey, 所有这些任务以及之前共享这个batchingKey的任务都将被添加到一个全局map中, key为batchingKey, 将这批任务中的第一个任务交给PrioritizedEsThreadPoolExecutor#execute执行;PrioritizedEsThreadPoolExecutor#execute: 线程池按照优先级等规则, 提交执行任务, 实际执行内容为TaskBatcher#runIfNotProcessed;TaskBatcher#runIfNotProcessed: 根据上面提到的第一个任务的batchingKey获取整批任务, 并调用MasterService.Batcher#run执行这批任务;MasterService.Batcher#run:
值得注意的一些功能
ingest node
###
从ES集群看分布式系统
数据隔离(?)
ES集群中每个节点只保存单独的一份数据, 该节点也只负责处理自己负责的这份数据
对ES工作感到困惑的点
索引时如何将对应的文档分配到某个分片中, 并将其复制到对应的副本中
搜索时如何将若干个分片中符合条件的结果组合
默认ZenDiscovery如何工作, 如何能够感知到新节点, 当一个节点down掉后, 如何保证ES还能正常提供服务; 当master down掉后, 如何重新选举新master
部分代码节选
Map<String, List<Path>> metaPlugins = new LinkedHashMap<>();
...
try (DirectoryStream<Path> subStream = Files.newDirectoryStream(plugin)) {
for (Path subPlugin : subStream) {
metaPlugins.computeIfAbsent(name, n -> new ArrayList<>()).add(subPlugin);
}
}