Lucene Related (TBD) 24 Mar 2014
Lucene是一个基于java的全文搜索开源项目。它主要完成两件事:建立索引和搜索
基本概念
Document:一条进行索引的记录,类似于数据库中的一条记录。任何需要被索引的对象都需要转化成Document,而搜索到的结果也以若干Document表示。Field:一个Document中的一个字段,类似于数据库中的Column。Term:它可以看作一个搜索单元,由两部分组成:字段名和对应于该字段的查询内容。Directory:索引存放位置,通常存放于文件系统内或内存中,常见实现为MMapDirectory, FSDirectory和RAMDirectorySegment:Lucene中的一个索引由多个子索引构成,也可以叫做一个segment。每一个segment都是完全独立的,它可以单独地被搜索。Query:Lucene提供了一系列查询,如最基础的TermQuery,或与其他Query组合使用的BooleanQuery,另外常见的Query有WildcardQuery,TermRangeQuery,PhraseQuery,利用这些Query我们可以作范围,通配符,短语查询。Scoring:Lucene以插件的形式提供了几种相似度模型用来计算Hits的score,包括向量空间模型,概率模型和语言模型。
Lucene程序的主要流程:
- 创建一个
Document实例,并向其添加Field(s) - 创建一个
IndexWriter,是用addDocument(s)方法向索引中添加记录。并调用close方法 - 调用QueryParser.parse(java.lang.String)将指定字符串构建为一个
Query对象 - 创建一个
IndexSearcher,将Query对象传给search方法
Indexing
在Lucene中最基本的概念是index,document,field,term。
一个Index由一系列Documents组成
一个Document由一系列Fields组成
一个Field由一系列命名Term组成
一个Term由一系列bytes组成
倒排索引
Lucene使用了倒排索引的方法,索引中存储Terms在哪些Document出现过,Lucene可以轻易的列出一个Term被哪些Documents所包含,这是自然包含关系(一个Document包含哪些Terms)的反转。这样做提高了基于Term搜索的效率。
Fields
- Stored:一个
Field可以被储存,在这种情况下,该Field的值以非倒排的形式完整地被保存下来。在某个Document被命中时,该Document中被标记为stored的所有fields都被包含在搜索结果中。 - Indexed:一个
Field可以被索引,该field被切分为多个Terms,并将这些terms以倒排的形式保存;同样,field也可以完整地作为一个term被索引,例如日期,作者名等。 一个字段可以同时被stored和indexed。
Segments
Lucene中的一个索引由多个子索引构成,也可以叫做一个segment。每一个segment都是完全独立的,它可以单独地被搜索。索引构建过程如下:
- 创建新的segments来存储新增加的documents
- 合并segments
IndexWriter
OpenMode
CREATE:始终创建一个新的索引,即使指定路径已经有索引存在。该情况下,如果已有readers打开了该索引,这些readers也无法看到新创建的索引,它们仍然搜索的是它们打开时的索引镜像。APPEND:打开一个已经存在的索引,如果指定路径不存在索引,IOException被抛出CREATE_OR_APPEND:指定路径不存在索引时,创建一个新的索引;否则打开该索引
Documents更新
使用addDocument方法添加一个document,使用deleteDocuments删除documents,另外可以使用updateDocument更新一个document(删除原document,然后添加整个新document)。当完成更新操作,需要调用close方法
这些改变并不会马上写入到索引文件中,而是先缓存在内存中,然后定期flush到文件中。Flush的触发条件主要有:
- 有足够的documents被添加,设置缓存documents数量方法为IndexWriterConfig.setMaxBufferedDocs(int)。
- 当缓存的documents占用足够大的内存空间,设置缓存空间方法为IndexWriterConfig.setRAMBufferSizeMB(double),为了提高索引效率,可以考虑增大缓存空间和缓存documents数。
- 被删除的terms和queries数,设置方法为IndexWriterConfig.setMaxBufferedDeleteTerms(int)
Flushing只是将缓存中的内容移动到索引,这些改变对于IndexReader来说并不是立即可见。在调用commit或close后,改变对于IndexReader才可见。
Flush可能会触发一个后台进程合并多个segments,该过程并不阻塞addDocument操作
打开一个IndexWriter实例,IndexWriter会在所使用的目录下建立一个lock file。试图打开另外一个使用相同目录的IndexWriter会抛出LockObtainFailedException。在使用相同目录的IndexReader从索引中删除documents时,相同异常同样会抛出
Directory的选择
64位的Windows和Linux平台使用MMapDirectory,除上述情况以外,windows平台使用SimpleFSDirectory,linux平台使用NIOFSDirectory。
public static FSDirectory open(File path, LockFactory lockFactory) throws IOException {
if ((Constants.WINDOWS || Constants.SUN_OS || Constants.LINUX)
&& Constants.JRE_IS_64BIT && MMapDirectory.UNMAP_SUPPORTED) { // UNMAP_SUPPORTED主要判断是否是Sun的jvm实现
return new MMapDirectory(path, lockFactory);
} else if (Constants.WINDOWS) {
return new SimpleFSDirectory(path, lockFactory);
} else {
return new NIOFSDirectory(path, lockFactory);
}
}- SimpleFSDirectory:一个
java.io.RandomAccessFile实现。由于多个线程访问同一文件会加锁,所以该实现在多线程操作下下会出现瓶颈 - NIOFSDirectory:使用
java.nio.channels.FileChannel实现。该实现避免了多线程访问同一文件的同步操作,但由于Windows平台下的JRE bug JDK-6265734,该实现不建议在Windows平台使用 - MMapDirectory:在64位环境中,Lucene开发者建议使用
MMapDirectory,它是由Virtual Memory实现。如果希望在32位环境下使用该实现,必须保证索引足够小。
有关MMapDirectory更详细的介绍,可以查看对其的相关介绍
Indexing Files示例
/** Index all text files under a directory.
* <p>
* This is a command-line application demonstrating simple Lucene indexing.
* Run it with no command-line arguments for usage information.
*/
public class IndexFiles {
private IndexFiles() {}
/** Index all text files under a directory. */
public static void main(String[] args) {
String usage = "java org.apache.lucene.demo.IndexFiles"
+ " [-index INDEX_PATH] [-docs DOCS_PATH] [-update]\n\n"
+ "This indexes the documents in DOCS_PATH, creating a Lucene index"
+ "in INDEX_PATH that can be searched with SearchFiles";
String indexPath = "index";
String docsPath = null;
boolean create = true;
for (int i = 0; i < args.length; i++) {
if ("-index".equals(args[i])) {
indexPath = args[i+1];
i++;
} else if ("-docs".equals(args[i])) {
docsPath = args[i+1];
i++;
} else if ("-update".equals(args[i])) {
create = false;
}
}
if (docsPath == null) {
System.err.println("Usage: " + usage);
System.exit(1);
}
final File docDir = new File(docsPath);
if (!docDir.exists() || !docDir.canRead()) {
System.out.println("Document directory '" +docDir.getAbsolutePath()+
"' does not exist or is not readable, please check the path");
System.exit(1);
}
Date start = new Date();
try {
System.out.println("Indexing to directory '" + indexPath + "'...");
Directory dir = FSDirectory.open(new File(indexPath));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40, analyzer);
if (create) {
// Create a new index in the directory, removing any
// previously indexed documents:
iwc.setOpenMode(OpenMode.CREATE);
} else {
// Add new documents to an existing index:
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
}
// Optional: for better indexing performance, if you
// are indexing many documents, increase the RAM
// buffer. But if you do this, increase the max heap
// size to the JVM (eg add -Xmx512m or -Xmx1g):
//
// iwc.setRAMBufferSizeMB(256.0);
IndexWriter writer = new IndexWriter(dir, iwc);
indexDocs(writer, docDir);
// NOTE: if you want to maximize search performance,
// you can optionally call forceMerge here. This can be
// a terribly costly operation, so generally it's only
// worth it when your index is relatively static (ie
// you're done adding documents to it):
//
// writer.forceMerge(1);
writer.close();
Date end = new Date();
System.out.println(end.getTime() - start.getTime() + " total milliseconds");
} catch (IOException e) {
System.out.println(" caught a " + e.getClass() +
"\n with message: " + e.getMessage());
}
}
/**
* Indexes the given file using the given writer, or if a directory is given,
* recurses over files and directories found under the given directory.
*
* NOTE: This method indexes one document per input file. This is slow. For good
* throughput, put multiple documents into your input file(s). An example of this is
* in the benchmark module, which can create "line doc" files, one document per line,
* using the
* <a href="../../../../../contrib-benchmark/org/apache/lucene/benchmark/byTask/tasks/WriteLineDocTask.html"
* >WriteLineDocTask</a>.
*
* @param writer Writer to the index where the given file/dir info will be stored
* @param file The file to index, or the directory to recurse into to find files to index
* @throws IOException If there is a low-level I/O error
*/
static void indexDocs(IndexWriter writer, File file)
throws IOException {
// do not try to index files that cannot be read
if (file.canRead()) {
if (file.isDirectory()) {
String[] files = file.list();
// an IO error could occur
if (files != null) {
for (int i = 0; i < files.length; i++) {
indexDocs(writer, new File(file, files[i]));
}
}
} else {
FileInputStream fis;
try {
fis = new FileInputStream(file);
} catch (FileNotFoundException fnfe) {
// at least on windows, some temporary files raise this exception with an "access denied" message
// checking if the file can be read doesn't help
return;
}
try {
// make a new, empty document
Document doc = new Document();
// Add the path of the file as a field named "path". Use a
// field that is indexed (i.e. searchable), but don't tokenize
// the field into separate words and don't index term frequency
// or positional information:
Field pathField = new StringField("path", file.getPath(), Field.Store.YES);
doc.add(pathField);
// Add the last modified date of the file a field named "modified".
// Use a LongField that is indexed (i.e. efficiently filterable with
// NumericRangeFilter). This indexes to milli-second resolution, which
// is often too fine. You could instead create a number based on
// year/month/day/hour/minutes/seconds, down the resolution you require.
// For example the long value 2011021714 would mean
// February 17, 2011, 2-3 PM.
doc.add(new LongField("modified", file.lastModified(), Field.Store.NO));
// Add the contents of the file to a field named "contents". Specify a Reader,
// so that the text of the file is tokenized and indexed, but not stored.
// Note that FileReader expects the file to be in UTF-8 encoding.
// If that's not the case searching for special characters will fail.
doc.add(new TextField("contents", new BufferedReader(new InputStreamReader(fis, "UTF-8"))));
if (writer.getConfig().getOpenMode() == OpenMode.CREATE) {
// New index, so we just add the document (no old document can be there):
System.out.println("adding " + file);
writer.addDocument(doc);
} else {
// Existing index (an old copy of this document may have been indexed) so
// we use updateDocument instead to replace the old one matching the exact
// path, if present:
System.out.println("updating " + file);
writer.updateDocument(new Term("path", file.getPath()), doc);
}
} finally {
fis.close();
}
}
}
}
} MMapDirectory
在lucene3.1中,lucene和solr在windows平台下开始默认使用MMapDirectory,在lucene3.3后,lucene和solr在64位平台上也开始默认使用这项配置。
在最早的计算机架构中,如果应用需要做一些IO操作,通常由应用发起一个syscall请求(开销很大)携带一个指向buffer的指针,然后在磁盘上进行传输操作。如果希望降低syscall数量,则需要开辟一个很大的buffer空间。这样做可以降低同步缓存与磁盘上的数据的操作的频率。这就是一些人希望把Lucene的index全部载入到RAM中。
Virtual Memory
为了解决上述问题,现代计算机架构包括Windows(NT+),Linux,Mac OS X以及Solaris利用它们的文件系统缓存和存储管理功能提供了一种更好的解决方案Virtual Memory。Virtual memory是现代计算机架构中必须的部分。它需要位于CPU中的memory management unit(MMU)的支持。它的工作原理很简单:每一个进程都有自己的virtual memory address space,所有libaries和堆栈都映射在这块virtual memory区域上。Virtual memory和物理内存没有任何关系,只是从进程的角度看,它的工作方式类似于内存,所以将其叫做virtual memory。应用可以像访问memory一样访问virtual memory,不需要关心其他应用同时也在使用内存,并且拥有它们自己的virtual memory address space。在virtual memory被首次访问时,底层OS和MMU协作,将virtual memory映射到real memory,这样,OS将所有进程的内存访问请求都分发到可用的real memory,这个过程对于应用来说完全是透明的
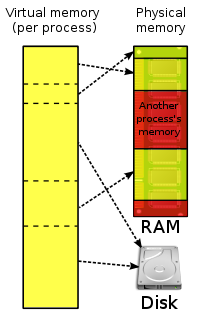 (image from Wikipedia [1], http://en.wikipedia.org/wiki/File:Virtual_memory.svg, licensed by CC BY-SA 3.0)
(image from Wikipedia [1], http://en.wikipedia.org/wiki/File:Virtual_memory.svg, licensed by CC BY-SA 3.0)
{kind=link}
如果没有足够的内存空间,OS可以将长时间不用的pages交换出去,释放物理内存。当一个进程试图访问一个被paged out的虚拟地址,它将会被重新载入到内存中。进程不需要做任何事,该过程对进程来说是透明的。因此,进程不需要知道有多少物理内存可用,但同时对于一些需要大量存储的应用(比如Lucene)来说,也会导致一些问题
Lucene & Virtual Memory
有了Virtual Memory这个功能,我们再考虑如果我们创建一个RAMDirectory,并将索引全部load到该directory中,这其实违背了OS的意愿:OS会在内存中cache所有的磁盘IO,而我们又将整个本来已经cache在内存中的内容copy到我们自己程序的virtual memory address space,这将损耗大量物理内存。由于物理内存有限,OS可能会将我们创建的巨大的RAMDirectory从物理内存移除,并将其放在磁盘的交换区。而且使用RAMDirectory,会引起一些GC和并发问题,由于数据被移至swap files,JVM的GC回收这些数据时,会导致大量的磁盘IO操作,缓慢的索引访问,分钟级的搜索延迟。
另外如果使用SimpleFSDirectory或NIOFSDirectory,为了在磁盘与文件系统cache,Java堆中的buffer之间传输数据,lucene发起了大量的syscall。而这些操作在每一次查询时都是必需的。
上述问题的解决方案就是MMapDirectory,它使用了virtual memory和mmap来访问磁盘文件。
mmap syscall告诉OS内核将整个Lucene索引映射到virtual memory地址空间,这样我们访问索引文件就像访问heap中的一个大的byte[]数组(在java中,这里是一个ByteBuffer实现,这依赖于java的mmap实现,ByteBuffer比byte[]慢)。这样我们不需要发起任何syscall,MMU和TLB(它会缓存磁盘中经常被访问的pages)会为我们handle所有的映射。如果数据只存储在磁盘上,MMU会发起一个中断,然后将索引数据拷贝到文件系统cache中。如果数据已经存在于文件系统cache中,MMU会将其直接映射到物理内存中,这样所有操作都在内存中进行。此外,我们不会浪费物理内存,因为我们直接操作OS cache,避免了所有上述提到的Java GC问题
上面所述对于我们的Lucene和Solr应用意味着什么?
- 我们应该为应用开辟尽可能小的内存空间(-Xmx),索引访问直接在OS cache上进行,这样也有助于Java GC collector的回收工作
- 释放尽可能多的物理内存,使它们作为OS的文件系统cache。Lucene应用占用太多的内存空间会影响性能,MMapDirectory不需要太多的堆>
为什么MMapDirectory最好工作在64位操作系统和JVM上?
最主要的限制在于32位平台中指针的个数,该数量可以是0到232 - 1任意地址,大约是4 gigabytes。大多数操作系统都需要保留一部分地址,所以可用的地址空间大约只有3 GB,这就意味着为任何进程所提供的地址空间只有3 GB左右,因此,我们无法将超过这个数量的索引映射到virtual memory。而且一旦我们映射了一个较大的文件,将不会再拥有足够的地址空间。而且随着现代内存工艺的发展,内存大小早已远远超过这个数字,由于32位平台virtual memory的局限,无法充分利用这些内存,这对于内存资源也是极大的浪费。
而在64位平台中,virtual memory地址空间大小达到264 - 1,超过18 quintillion bytes。当然大部分系统仍需要保留一部分地址,所以操作系统将该数字限制到47bits(Windows为43bits),但也足够映射TB级的数据。
几个容易被误解的要点
- MMapDirectory不会额外消耗内存,映射的索引文件不会受限于物理内存的大小。使用mmap,lucene只使用virtual memory,而不是物理内存。而64位平台的地址空间是足够
- MMapDirectory不会将整个索引都载入到物理内存。Lucene只是将索引映射到地址空间,这样方便定位。Java和OS都提供方法来将其载入到内存(如果内存有足够的空间的话),但lucene并没有使用这项功能。
配置操作系统以及JVM优化Lucene或Solr
对于操作系统来说,默认配置就可以很好地工作。可以查看"ulimit -v"和"ulimit -m"的结果为“unlimited”,否则在我们打开索引时,MMapDirectory会报“mmap failed”的错误。如果在有大量很大的索引,而这些索引由许多segments组成仍然有该错误,可以调节/etc/sysctl.conf,vm.max_map_count的默认值为65530,可以将其调大。
对于JVM,我们已经知道lucene应用应该占用尽量小的内存,重新审视自己的程序,为其设置真正需要的大小。一般来说,该数字(-Xmx)不应该超过总内存的1/4。将足够的内存空间留给OS cache。当然也不需要为OS留像索引大小一样大的内存,因为系统内核会将索引中经常使用的pages page in内存。
使用top(ubuntu下为iotop)查看Lucene进程如果有大量swap in/swap out的现象的话,将lucene程序的堆占用空间调小。如果还有大量磁盘IO的话,添加更多的内存。最后,购买SSDs(big grin)
该文摘自Use Lucene’s MMapDirectory on 64bit platforms, please!
Searching
Lucene提供了大量的Query实现,这些实现可以组合在一起使用以满足复杂的搜索请求。在程序中使用IndexSearcher.search(Query, int),IndexSearcher.search(Query, Filter, int)执行搜索请求。一旦一个Query被创建并提交给IndexSearcher,Lucene会根据Weight实现和Scorer实力对搜索结果评分。
Query实现
TermQuery
TermQuery是最基本也是使用频率最好的一种查询。TermQuery匹配所有包含指定Term的Documents,也就是说一个词出现在指定Field中。
匹配字段fieldName中包含term的所有documents
TermQuery tq = new TermQuery(new Term("fieldName", "term"));BooleanQuery
BooleanQuery可以将其他类型的Query根据指定的逻辑关系组合在一起,形成复杂的查询请求。一个BooleanQuery可以包含多个BooleanClauses,每一个BooleanClause包含一个Query实例,和一个描述该Query和其他BooleanClauses如何组合在一起的操作符:BooleanClause.Occur,该操作符有以下几种:
SHOULD- 结果集中的document可以满足此条件,但并不是必须的。如果一个BooleanQuery包含的条件都是SHOULD,那么documents中只要满足这些条件中的一个就可以纳入结果集MUST- 结果集中每一个document必须满足此条件。MUST_NOT- 结果集中没有任何document满足该条件。
BooleanQuery由两个以上的Query构造而成,但是如果太多的条件加入到BooleanQuery,在搜索时会抛出TooManyClauses异常。默认限制为1024,可以通过BooleanQuery.setMaxClauseCount(int)修改该限制
Phrases
短语查询是一类比较常见的查询,它匹配包含特定短语的documents
PhraseQuery- 就是通过短语来检索,比如待查词为long hair,匹配所有指定Field包含long hair的documents。如果Field中是long black hair的document,则不能匹配。如果希望匹配该document,则设置slop为1,该数字为Term的单词的间隔。-
MultiPhraseQuery- 多短语查询,如果要实现“a (bc d) e”,需要用”a b e”,“a c e”和”a d e”三个PhraseQuery来实现。
以下分别使用短语查询和多短语查询实现上述功能
// 多短语查询
MultiPhraseQuery query = new MultiPhraseQuery();
query.add(new Term("title", "a"));
Term t1 = new Term("title","b");
Term t2 = new Term("title","c");
Term t2 = new Term("title","d");
query.add(new Term[]{t1, t2, t3});
query.add(new Term("title", "e"));
// 短语查询实现
PhraseQuery query1 = new PhraseQuery();
query1.add(new Term("title", "a"));
query1.add(new Term("title", "b"));
query1.add(new Term("title", "e"));
PhraseQuery query2 = new PhraseQuery();
query2.add(new Term("title", "a"));
query2.add(new Term("title", "c"));
query2.add(new Term("title", "e"));
PhraseQuery query3 = new PhraseQuery();
query3.add(new Term("title", "a"));
query3.add(new Term("title", "d"));
query3.add(new Term("title", "e"));
BooleanQuery query = new BooleanQuery();
query.add(query1, SHOULD);
query.add(query2, SHOULD);
query.add(query3, SHOULD);IndexSearcher
程序通常只需要调用IndexSearcher.search(Query, int)和IndexSearcher.search(Query, Filter, int)即可完成搜索。基于性能考虑,如果索引不变的话,多次搜索应该使用一个IndexSearcher实例,而不是每一次搜索都新建一个实例。如果索引已经改变,并且希望这些改变能够被搜索到,则使用DirectoryReader.openIfChanged(DirectoryReader)获取一个新的reader,并是用该reader重新构建IndexSearcher。此外,对于低延迟的搜索需求,可以使用DirectoryReader.open(IndexWriter, boolean)获取一个近实时的reader。建立IndexSearcher相对于建立IndexReader成本较小。
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/** Simple command-line based search demo. */
public class SearchFiles {
private SearchFiles() {}
/** Simple command-line based search demo. */
public static void main(String[] args) throws Exception {
String usage =
"Usage:\tjava org.apache.lucene.demo.SearchFiles [-index dir]" +
" [-field f] [-repeat n] [-queries file] [-query string] [-raw] " +
"[-paging hitsPerPage]\n\nSee http://lucene.apache.org/core/4_1_0/demo/ for details.";
if (args.length > 0 && ("-h".equals(args[0]) || "-help".equals(args[0]))) {
System.out.println(usage);
System.exit(0);
}
String index = "index";
String field = "contents";
String queries = null;
int repeat = 0;
boolean raw = false;
String queryString = null;
int hitsPerPage = 10;
for(int i = 0;i < args.length;i++) {
if ("-index".equals(args[i])) {
index = args[i+1];
i++;
} else if ("-field".equals(args[i])) {
field = args[i+1];
i++;
} else if ("-queries".equals(args[i])) {
queries = args[i+1];
i++;
} else if ("-query".equals(args[i])) {
queryString = args[i+1];
i++;
} else if ("-repeat".equals(args[i])) {
repeat = Integer.parseInt(args[i+1]);
i++;
} else if ("-raw".equals(args[i])) {
raw = true;
} else if ("-paging".equals(args[i])) {
hitsPerPage = Integer.parseInt(args[i+1]);
if (hitsPerPage <= 0) {
System.err.println("There must be at least 1 hit per page.");
System.exit(1);
}
i++;
}
}
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(index)));
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
BufferedReader in = null;
if (queries != null) {
in = new BufferedReader(new InputStreamReader(new FileInputStream(queries), "UTF-8"));
} else {
in = new BufferedReader(new InputStreamReader(System.in, "UTF-8"));
}
QueryParser parser = new QueryParser(Version.LUCENE_40, field, analyzer);
while (true) {
if (queries == null && queryString == null) { // prompt the user
System.out.println("Enter query: ");
}
String line = queryString != null ? queryString : in.readLine();
if (line == null || line.length() == -1) {
break;
}
line = line.trim();
if (line.length() == 0) {
break;
}
Query query = parser.parse(line);
System.out.println("Searching for: " + query.toString(field));
if (repeat > 0) { // repeat & time as benchmark
Date start = new Date();
for (int i = 0; i < repeat; i++) {
searcher.search(query, null, 100);
}
Date end = new Date();
System.out.println("Time: "+(end.getTime()-start.getTime())+"ms");
}
doPagingSearch(in, searcher, query, hitsPerPage, raw, queries == null && queryString == null);
if (queryString != null) {
break;
}
}
reader.close();
}
/**
* This demonstrates a typical paging search scenario, where the search engine presents
* pages of size n to the user. The user can then go to the next page if interested in
* the next hits.
*
* When the query is executed for the first time, then only enough results are collected
* to fill 5 result pages. If the user wants to page beyond this limit, then the query
* is executed another time and all hits are collected.
*
*/
public static void doPagingSearch(BufferedReader in, IndexSearcher searcher, Query query,
int hitsPerPage, boolean raw, boolean interactive) throws IOException {
// Collect enough docs to show 5 pages
TopDocs results = searcher.search(query, 5 * hitsPerPage);
ScoreDoc[] hits = results.scoreDocs;
int numTotalHits = results.totalHits;
System.out.println(numTotalHits + " total matching documents");
int start = 0;
int end = Math.min(numTotalHits, hitsPerPage);
while (true) {
if (end > hits.length) {
System.out.println("Only results 1 - " + hits.length +" of "
+ numTotalHits + " total matching documents collected.");
System.out.println("Collect more (y/n) ?");
String line = in.readLine();
if (line.length() == 0 || line.charAt(0) == 'n') {
break;
}
hits = searcher.search(query, numTotalHits).scoreDocs;
}
end = Math.min(hits.length, start + hitsPerPage);
for (int i = start; i < end; i++) {
if (raw) { // output raw format
System.out.println("doc="+hits[i].doc+" score="+hits[i].score);
continue;
}
Document doc = searcher.doc(hits[i].doc);
String path = doc.get("path");
if (path != null) {
System.out.println((i+1) + ". " + path);
String title = doc.get("title");
if (title != null) {
System.out.println(" Title: " + doc.get("title"));
}
} else {
System.out.println((i+1) + ". " + "No path for this document");
}
}
if (!interactive || end == 0) {
break;
}
if (numTotalHits >= end) {
boolean quit = false;
while (true) {
System.out.print("Press ");
if (start - hitsPerPage >= 0) {
System.out.print("(p)revious page, ");
}
if (start + hitsPerPage < numTotalHits) {
System.out.print("(n)ext page, ");
}
System.out.println("(q)uit or enter number to jump to a page.");
String line = in.readLine();
if (line.length() == 0 || line.charAt(0)=='q') {
quit = true;
break;
}
if (line.charAt(0) == 'p') {
start = Math.max(0, start - hitsPerPage);
break;
} else if (line.charAt(0) == 'n') {
if (start + hitsPerPage < numTotalHits) {
start+=hitsPerPage;
}
break;
} else {
int page = Integer.parseInt(line);
if ((page - 1) * hitsPerPage < numTotalHits) {
start = (page - 1) * hitsPerPage;
break;
} else {
System.out.println("No such page");
}
}
}
if (quit) break;
end = Math.min(numTotalHits, start + hitsPerPage);
}
}
}
}Scoring
Lucene支持3种打分机制: