the Principle of Search Engine 24 Mar 2014
对内容进行索引
假设我们有一系列的文章需要进行索引, 我们将每一篇文章看成一个Document, 而这个Document中包含了多个字段(Fields), 如作者, 出版日期, 前言, ISBN, 内容等, 比如我们需要查找内容包含”Search Engine”的章节, 对于正常的逻辑, 我们需要迭代整篇文章的内容, 去匹配”Search Engine”这个词, 但是这样的效率是极低的, 每一次搜索, 都需要将整篇文章进行一遍搜索, 所以, 就提出了著名的”倒排索引方式”
倒排索引的过程:
- 首先我们需要为这一系列的
Documents分配一个编号, 姑且叫做DocId, 则对于[DocumentA, DocumentB, DocumentC], 我们分别为他们设置的编号为[d1, d2, d3]` - 我们将这些
Documents按照Field进行索引, 为了简明起见, 只对内容进行索引, 我们将一个Document的内容按照一定的规则进行分词, 当然也有一些字段我是不希望被分词的, 比如作者等信息等. 想象一下我们将”One world, one dream. “切分为[one, world, one, dream]. 我们将切分后的每一个值叫做一个Term, 这样我们建立一个以Term为基准的索引, 可以把它简单比作以Term为key的一个Map或字典. 上述句子可以把它索引为Term(“one”) -> d1:2, Term(“dream”) -> d1:1, Term(“world”) -> d1:1, 其中Term(“one”)就是一个Term, 它是索引以及搜索时的最小单位, “d1:2”中的的d1是该Term出现的文章编号,2是Term出现在该文档中的次数. 当然除了这两个维度的信息, 我们还可以保存该Term`的其他相关信息, 比如出现位置等. - 假设我们将所有
Document进行了索引, 得到的就是Term(“one”) -> [d1:2; d2:1; d3:3], Term(“dream”) -> [d1:1, d3:2], Term(“world”) -> d1:1 - 当我们需要查询单词
one时, 我们通过索引立刻就能够找到one这个单词出现在DocumentA, DocumentB, DocumentC中, 包括他们的分别出现的次数. - 另外当我们对多个字段进行索引时, 这就需要在每一个Field中包含这些Term信息
搜索条件的解析
搜索条件分为两种,BooleanQuery和Full-Text Query
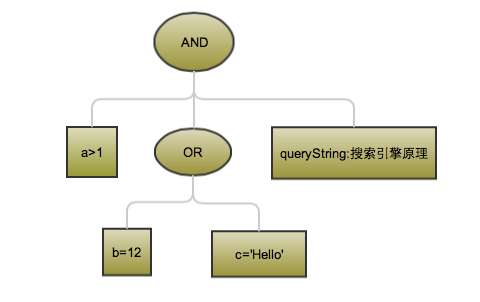
- BooleanQuery:类型 a>1 AND (b=12 OR c=’Hello’),该类Query具有明确的逻辑性,结果只有是或否
- Full-Text Query:一般针对文本搜索,对搜索词,进行分词,完全匹配搜索词,可以纳入结果集,部分匹配也有可能纳入结果集,但排序时,可能会排在靠后的位置。
搜索引擎会将用户输入的条件解析为查询树
针对Full-Text Query, 将文本进行分词,并形成一个具有逻辑的文本序列,例如将{queryString:搜索引擎原理}分词后形成{text:搜索 text:引擎 text:原理},并根据搜索引擎默认设置查询操作符或用户指定的查询操作符来确定分词序列直接的逻辑关系,如果用户希望得到相对精确的搜索结果,则分词序列可能转换为{+text:搜索 +text:引擎 +text:原理}, 3个词必须全部命中才能纳入到结果中去
则查询树转变为一个简单的逻辑查询树
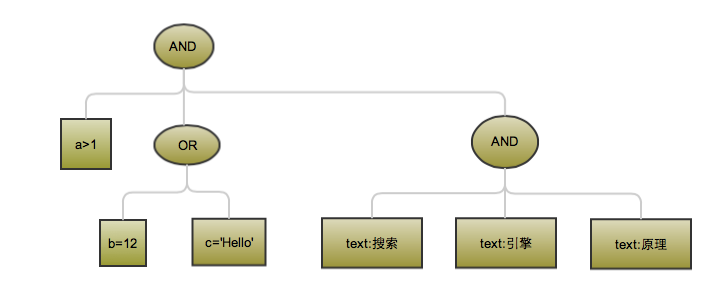
搜索结果命中
针对上一步产生的查询树,将索引与该查询树进行比对,将符合查询条件的搜索结果纳入到搜索结果中
搜索结果排序
1. 链接分析排序(PageRank)
a) 链接的重要性(互联网的排序中,该项会作为一个排序因子对排序结果进行影响)
可以假设如果一个网页被多次引用,则认为该网页是重要的,如果被一个重要的网页所引用,则认为自身也是重要的。
b) 文档内容的相关性
- 可以假设一个词(Term)在一篇文档中出现次数越多,则认为该文档对于该Term的相关性越高,但是当一篇10000词的文档Doc1中TermA出现3次,而一篇100词的文档Doc2中TermA出现2次时,实际上Doc2对于TermA的相关性更高。所以我们可以认为Term在一篇文档中出现频率越高,文档对于该Term的相关性越高。
- 不同词对于文档来说重要性也不同,如果共有10000份文档,TermA在1000份文档中出现过,TermB在100份文档出现过,那么则认为TermB的权重比TermA的要高。如果搜索TermA和TermB,匹配到TermB的结果应适当排在前面
- 对于“的”,“是”,“中”,“和”,“得”,“地”之类的无意义的连词,不应该对文档排序产生影响。这一类词称之为“stopwords”。他们的权重应该为0
详见http://zh.wikipedia.org/wiki/TF-IDF
2.余弦相似度
我们可以将一个文档想象为一个向量,如果另外一个文档与该文档一致,那么这两个向量的夹角应该为0,如果两个向量的夹角很小,纳闷则认为这两个文档的相关度很高。